Parallèle
Exécuter plusieurs blocs en parallèle pour accélérer le traitement des workflows
Le bloc Parallèle est un bloc conteneur dans Scrydon qui vous permet d'exécuter plusieurs instances de blocs en simultané.
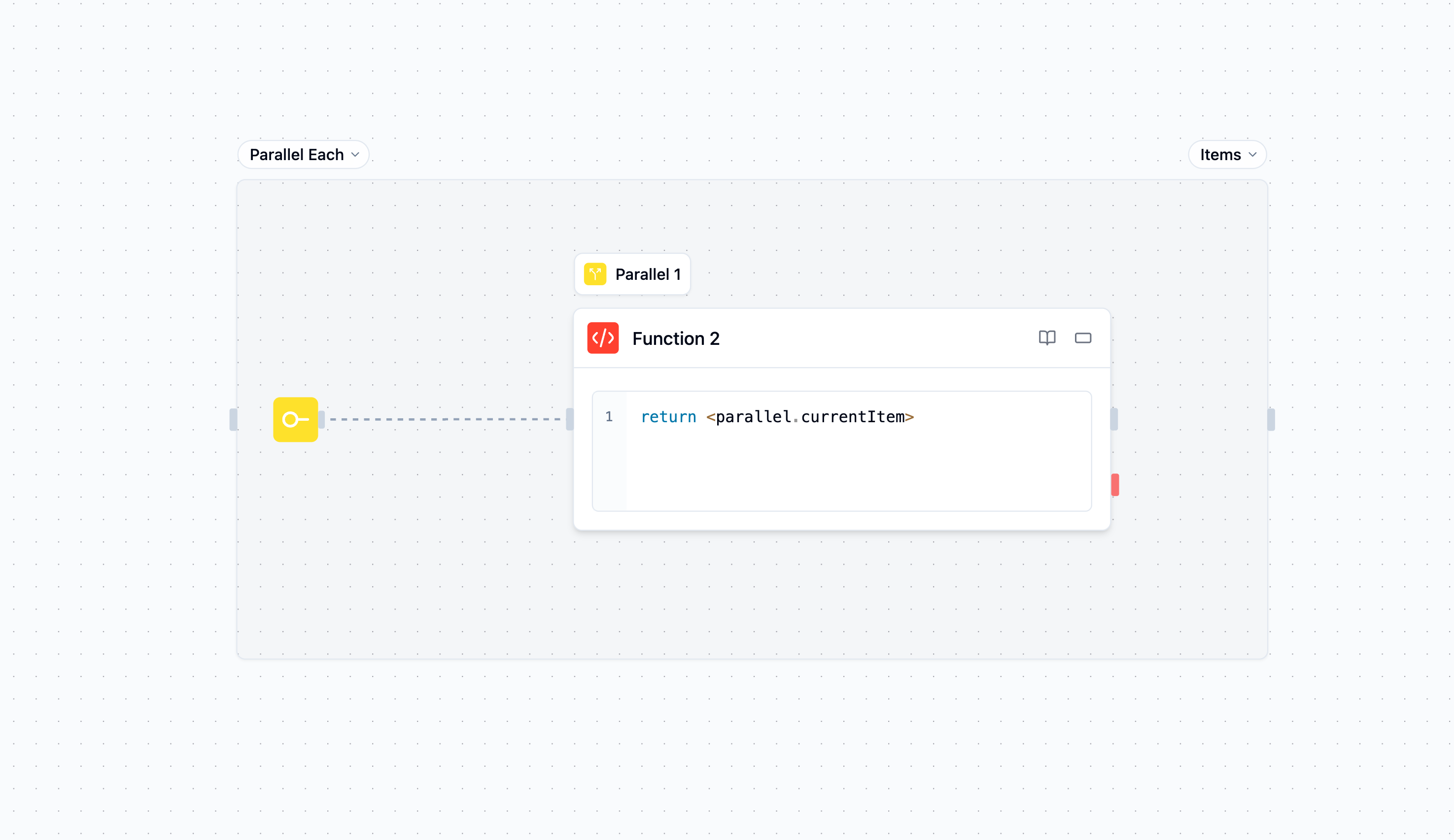
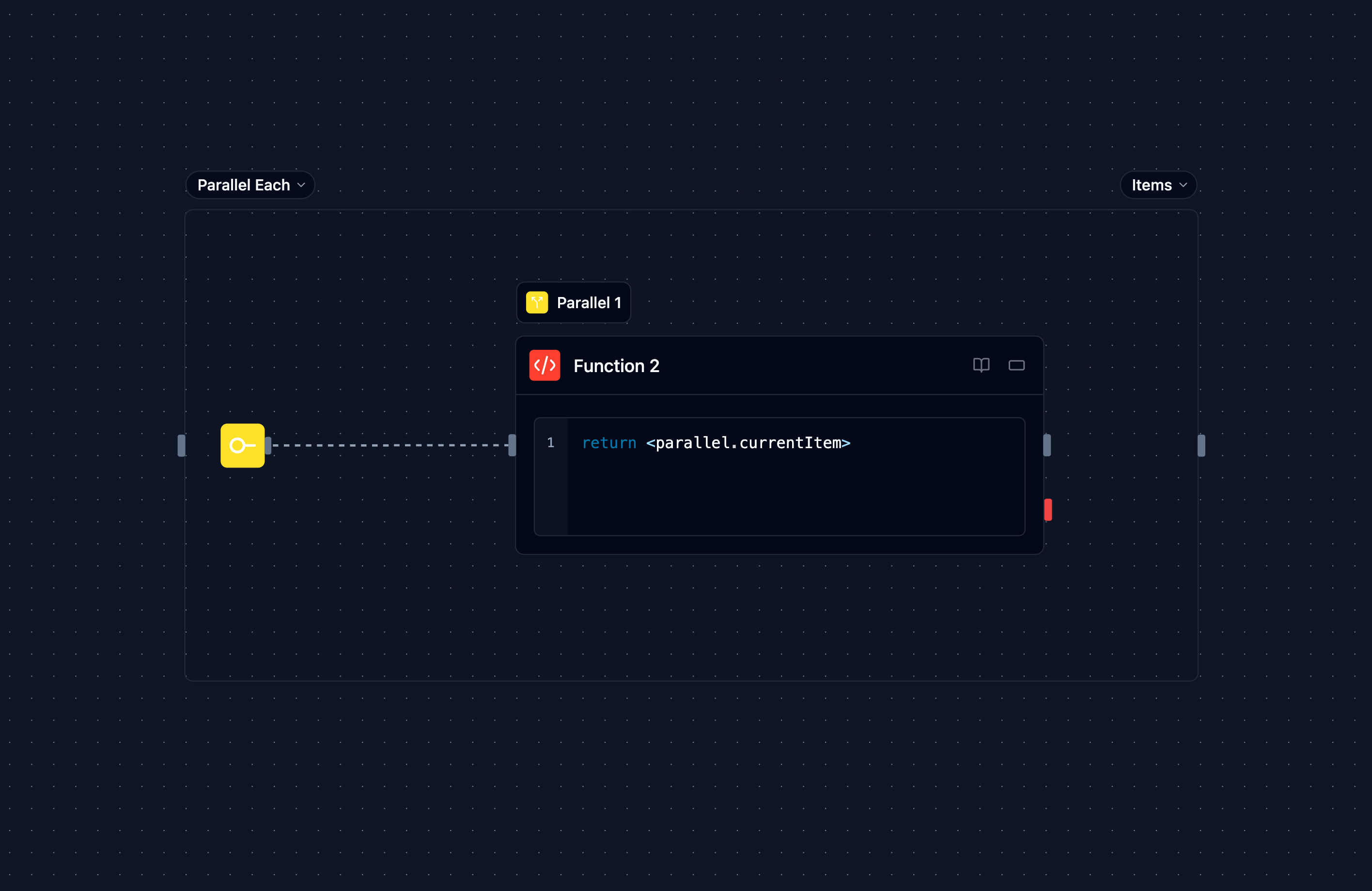
Les blocs parallèles sont des nœuds conteneurs qui exécutent leur contenu plusieurs fois simultanément, contrairement aux boucles qui s'exécutent séquentiellement.
Vue d'ensemble
Le bloc Parallèle vous permet de :
Distribuer le travail : Traiter plusieurs éléments en simultané
Accélérer l'exécution : Exécuter des opérations indépendantes simultanément
Traiter des opérations en masse : Traiter efficacement de grands ensembles de données
Agréger les résultats : Collecter les sorties de toutes les exécutions parallèles
Options de configuration
Type de parallèle
Choisissez entre deux types d'exécution parallèle :
Exécute un nombre fixe d'instances parallèles. Utilisez ceci lorsque vous devez exécuter la même opération plusieurs fois en simultané.
Exemple : Exécuter 5 instances parallèles
- Instance 1 ┐
- Instance 2 ├─ Toutes s'exécutent simultanément
- Instance 3 │
- Instance 4 │
- Instance 5 ┘Distribue une collection sur des instances parallèles. Chaque instance traite un élément de la collection simultanément.
Exemple : Traiter ["task1", "task2", "task3"] en parallèle
- Instance 1 : Traite "task1" ┐
- Instance 2 : Traite "task2" ├─ Toutes s'exécutent simultanément
- Instance 3 : Traite "task3" ┘Utiliser les blocs parallèles
Créer un bloc Parallèle
- Faites glisser un bloc Parallèle depuis la barre d'outils vers votre canevas
- Configurez le type de parallèle et les paramètres
- Faites glisser un seul bloc à l'intérieur du conteneur parallèle
- Connectez le bloc selon les besoins
Accéder aux résultats
Après la complétion d'un bloc parallèle, vous pouvez accéder aux résultats agrégés :
<parallel.results>: Tableau des résultats de toutes les instances parallèles
Exemples d'utilisation
Traitement d'API en masse
Scénario : Traiter plusieurs appels API simultanément
- Bloc Parallèle avec une collection de points d'entrée API
- À l'intérieur du parallèle : le bloc API appelle chaque point d'entrée
- Après le parallèle : traiter toutes les réponses ensemble
Traitement IA multi-modèles
Scénario : Obtenir des réponses de plusieurs modèles IA
- Parallèle basé sur le nombre défini à 3 instances
- À l'intérieur du parallèle : agent configuré avec un modèle différent par instance
- Après le parallèle : comparer et sélectionner la meilleure réponse
Fonctionnalités avancées
Agrégation des résultats
Les résultats de toutes les instances parallèles sont collectés automatiquement :
// Dans un bloc Fonction après le parallèle
const allResults = input.parallel.results;
// Retourne : [result1, result2, result3, ...]Isolation des instances
Chaque instance parallèle s'exécute indépendamment :
- Portées de variables séparées
- Pas d'état partagé entre les instances
- Les échecs d'une instance n'affectent pas les autres
Limitations
Les blocs conteneurs (Boucles et Parallèles) ne peuvent pas être imbriqués les uns dans les autres. Cela signifie :
- Vous ne pouvez pas placer un bloc Boucle à l'intérieur d'un bloc Parallèle
- Vous ne pouvez pas placer un autre bloc Parallèle à l'intérieur d'un bloc Parallèle
- Vous ne pouvez pas placer un bloc conteneur à l'intérieur d'un autre bloc conteneur
Les blocs parallèles ne peuvent contenir qu'un seul bloc. Vous ne pouvez pas avoir plusieurs blocs connectés les uns aux autres à l'intérieur d'un parallèle — seul le premier bloc s'exécuterait dans ce cas.
Bien que l'exécution parallèle soit plus rapide, tenez compte de :
- Les limites de débit des API lors de requêtes concurrentes
- L'utilisation de la mémoire avec de grands ensembles de données
- Le maximum de 20 instances concurrentes pour éviter l'épuisement des ressources
Parallèle vs Boucle
Comprendre quand utiliser chacun :
| Fonctionnalité | Parallèle | Boucle |
|---|---|---|
| Exécution | Concurrente | Séquentielle |
| Vitesse | Plus rapide pour les opérations indépendantes | Plus lente mais ordonnée |
| Ordre | Aucun ordre garanti | Maintient l'ordre |
| Cas d'usage | Opérations indépendantes | Opérations dépendantes |
| Utilisation des ressources | Plus élevée | Plus faible |
Entrées et sorties
Type de parallèle : Choisir entre 'count' ou 'collection'
Nombre : Nombre d'instances à exécuter (basé sur le nombre)
Collection : Tableau ou objet à distribuer (basé sur la collection)
parallel.currentItem : Élément pour cette instance
parallel.index : Numéro d'instance (à partir de 0)
parallel.items : Collection complète (basé sur la collection)
parallel.results : Tableau de tous les résultats d'instances
Accès : Disponible dans les blocs après le parallèle
Bonnes pratiques
- Opérations indépendantes uniquement : Assurez-vous que les opérations ne dépendent pas les unes des autres
- Gérer les limites de débit : Ajoutez des délais ou une limitation pour les workflows intensifs en API
- Gestion des erreurs : Chaque instance doit gérer ses propres erreurs de manière élégante