Agent
Create powerful AI agents using any LLM provider
The Agent block serves as the interface between your workflow and Large Language Models (LLMs). It executes inference requests against various AI providers, processes natural language inputs according to defined instructions, and generates structured or unstructured outputs for downstream consumption.
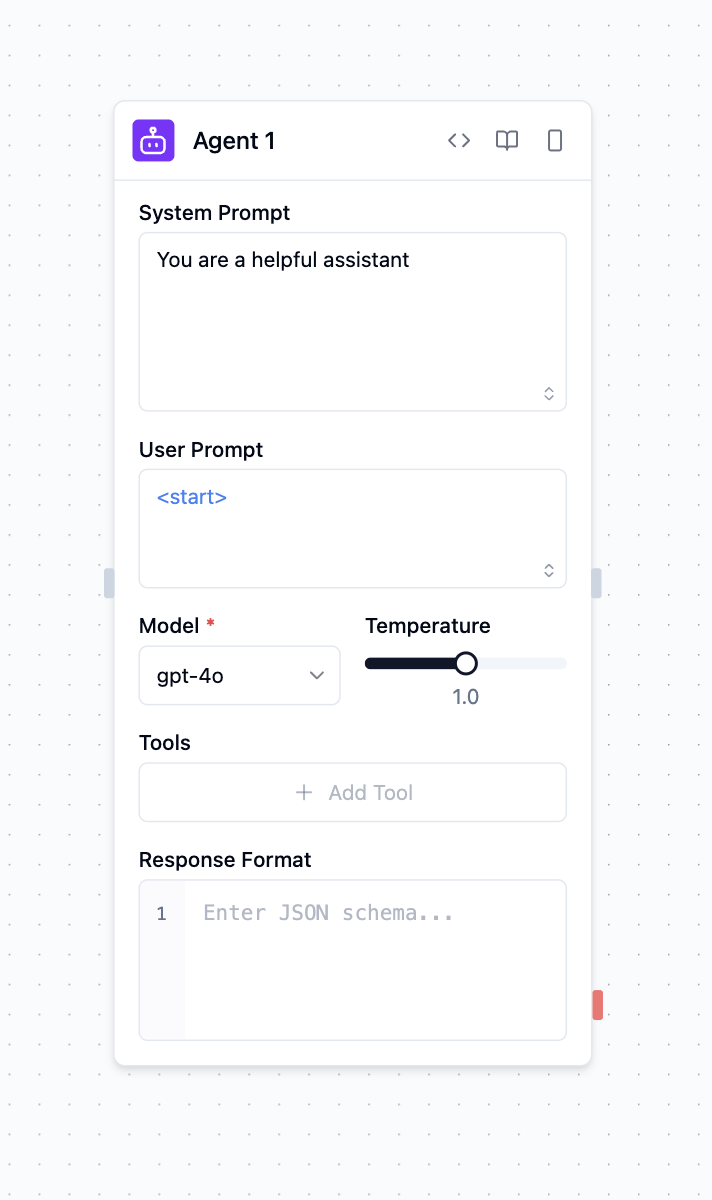
Overview
The Agent block enables you to:
Process natural language: Analyze user input and generate contextual responses
Execute AI-powered tasks: Perform content analysis, generation, and decision-making
Call external tools: Access APIs, databases, and services during processing
Generate structured output: Return JSON data that matches your schema requirements
Configuration Options
System Prompt
The system prompt establishes the agent's operational parameters and behavioral constraints. This configuration defines the agent's role, response methodology, and processing boundaries for all incoming requests.
You are a helpful assistant that specializes in financial analysis.
Always provide clear explanations and cite sources when possible.
When responding to questions about investments, include risk disclaimers.User Prompt
The user prompt represents the primary input data for inference processing. This parameter accepts natural language text or structured data that the agent will analyze and respond to. Input sources include:
- Static Configuration: Direct text input specified in the block configuration
- Dynamic Input: Data passed from upstream blocks through connection interfaces
- Runtime Generation: Programmatically generated content during workflow execution
Model Selection
The Agent block doesn't reference a vendor by name. It declares a need for the LLM capability and the platform's integration registry resolves the request against installed providers — first by per-call override, then by org policy, then by automatic pick across installed vendors.
Vendors that contribute the LLM capability today:
- Anthropic — Claude family via the Messages API
- OpenAI — GPT family via
openai-chat-v1 - Mistral — Mistral models via
openai-chat-v1 - AWS Bedrock — foundation models via
bedrock-converse-v1 - Azure AI Foundry — per-org deployed models
- Google Cloud (Vertex AI) — Gemini via
openai-chat-v1 - Ollama — local LLMs via OpenAI-compatible endpoint
- vLLM — self-hosted high-throughput inference
Temperature
Control the creativity and randomness of responses:
More deterministic, focused responses. Best for factual tasks, customer support, and situations where accuracy is critical.
Balanced creativity and focus. Suitable for general purpose applications that require both accuracy and some creativity.
More creative, varied responses. Ideal for creative writing, brainstorming, and generating diverse ideas.
The temperature range (0-1 or 0-2) varies depending on the selected model.
API Key
Credentials are not configured on the Agent block itself. Each LLM-capable vendor stores its credential through the integrations flow, and the registry hands the live access token to the runtime at execute time.
Tools
Tools extend the agent's capabilities through function calling. Tools come from vendor products — never from a flat global pool. When you click "Add tools" on the Agent block you pick from the installed vendor catalog: each product contributes its own toolset (e.g. google:gmail contributes send-mail, list-messages, …; scrydon:knowledge contributes knowledge-rag-search).
Tool integration process:
- Open the Tools section on the Agent block
- Pick a vendor product from the installed catalog
- Add one or more of the product's tools and (where required) configure a credential
Where tools come from:
- Built-in: see
scrydon— Knowledge, Memory, Storage, Tables, Workflow, Web, SMTP, SMS, Guardrails, A2A, SSH - Productivity & storage: Google, Microsoft, Atlassian, GitHub, Salesforce, …
- Custom: build your own with the Integrations Authoring SDK and upload through Settings
Tool Execution Control:
- Auto: Model determines tool invocation based on context and necessity
- Required: Tool must be called during every inference request
- None: Tool definition available but excluded from model context
Response Format
The Response Format parameter enforces structured output generation through JSON Schema validation. This ensures consistent, machine-readable responses that conform to predefined data structures:
{
"name": "user_analysis",
"schema": {
"type": "object",
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"]
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1
}
},
"required": ["sentiment", "confidence"]
}
}This configuration constrains the model's output to comply with the specified schema, preventing free-form text responses and ensuring structured data generation.
Accessing Results
After an agent completes, you can access its outputs:
<agent.content>: The agent's response text or structured data<agent.tokens>: Token usage statistics (prompt, completion, total)<agent.tool_calls>: Details of any tools the agent used during execution<agent.cost>: Estimated cost of the API call (if available)
Advanced Features
Memory Integration
Agents can maintain context across interactions using the memory system:
// In a Function block before the agent
const memory = {
conversation_history: previousMessages,
user_preferences: userProfile,
session_data: currentSession
};Structured Output Validation
Use JSON Schema to ensure consistent, machine-readable responses:
{
"type": "object",
"properties": {
"analysis": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"categories": {"type": "array", "items": {"type": "string"}}
},
"required": ["analysis", "confidence"]
}Error Handling
Agents automatically handle common errors:
- API rate limits with exponential backoff
- Invalid tool calls with retry logic
- Network failures with connection recovery
- Schema validation errors with fallback responses
Inputs and Outputs
System Prompt: Instructions defining agent behavior and role
User Prompt: Input text or data to process
Model: AI model selection (OpenAI, Anthropic, Google, etc.)
Temperature: Response randomness control (0-2)
Tools: Array of available tools for function calling
Response Format: JSON Schema for structured output
agent.content: Agent's response text or structured data
agent.tokens: Token usage statistics object
agent.tool_calls: Array of tool execution details
agent.cost: Estimated API call cost (if available)
Content: Primary response output from the agent
Metadata: Usage statistics and execution details
Access: Available in blocks after the agent
Example Use Cases
Customer Support Automation
Scenario: Handle customer inquiries with database access
- User submits support ticket via API block
- Agent processes inquiry with product database tools
- Agent generates response and creates follow-up ticket
- Response block sends reply to customer
Multi-Model Content Analysis
Scenario: Analyze content with different AI models
- Function block processes uploaded document
- Agent with GPT-4o performs technical analysis
- Agent with Claude analyzes sentiment and tone
- Function block combines results for final report
Tool-Powered Research Assistant
Scenario: Research assistant with web search and document access
- User query received via input
- Agent searches the web using
scrydon:web(fetch-webpage) orgoogle:search(Custom Search) - Agent retrieves internal docs through
scrydon:knowledge(RAG search) - Agent compiles comprehensive research report
Best Practices
- Be specific in system prompts: Clearly define the agent's role, tone, and limitations. The more specific your instructions are, the better the agent will be able to fulfill its intended purpose.
- Choose the right temperature setting: Use lower temperature settings (0-0.3) when accuracy is important, or increase temperature (0.7-2.0) for more creative or varied responses
- Leverage tools effectively: Integrate tools that complement the agent's purpose and enhance its capabilities. Be selective about which tools you provide to avoid overwhelming the agent. For tasks with little overlap, use another Agent block for the best results.